
本記事では、(株)データミックス![]() の「気象データアナリスト養成講座」を受けた感想や、講義メモをまとめます。
の「気象データアナリスト養成講座」を受けた感想や、講義メモをまとめます。
今回は、2023年2月4日に受けた、ブートキャンプステップ2日目の内容です。
本記事では、講義後半でおこなわれたRの演習についてまとめています。
講義前半の「統計的・確率的アプローチ」については、以下の記事をご参照ください。

R学習①:Rによる可視化(ggplot)
講義2日目の予習の時点で、Rによる可視化(ggplot)とEDAという項目がありました。
「ggplot...?EDA...?」となったので、そもそもggplotやEDAとは何なのか、というところから予習を始めました。
講義のなかでも、Rでの分析について詳しく解説されます。
Rによる可視化(ggplot)について
まずは、Rによる可視化(ggplot)について見ていきます。
ggplotとは、R言語でデータをグラフにできる拡張機能です。
棒グラフや散布図、ヒストグラムなどのグラフを、シンプルなプログラミングコードで描画できるようになります。
ちなみにggplotの「gg」は、「grammar of graphics(グラフ作成のための文法)」という意味です。
"iris"データを使ってみる
予習用に共有されていたファイルでは、"iris"というデータを読み込んでグラフを描画するコードが書かれていました。
調べてみると、"iris"とは「アヤメ」のこと。
Rでは既存パッケージとして"iris"のデータが用意されているようです。
データの中身は、3種類のアヤメの「がくの長さと幅」「花びらの長さと幅」でした。
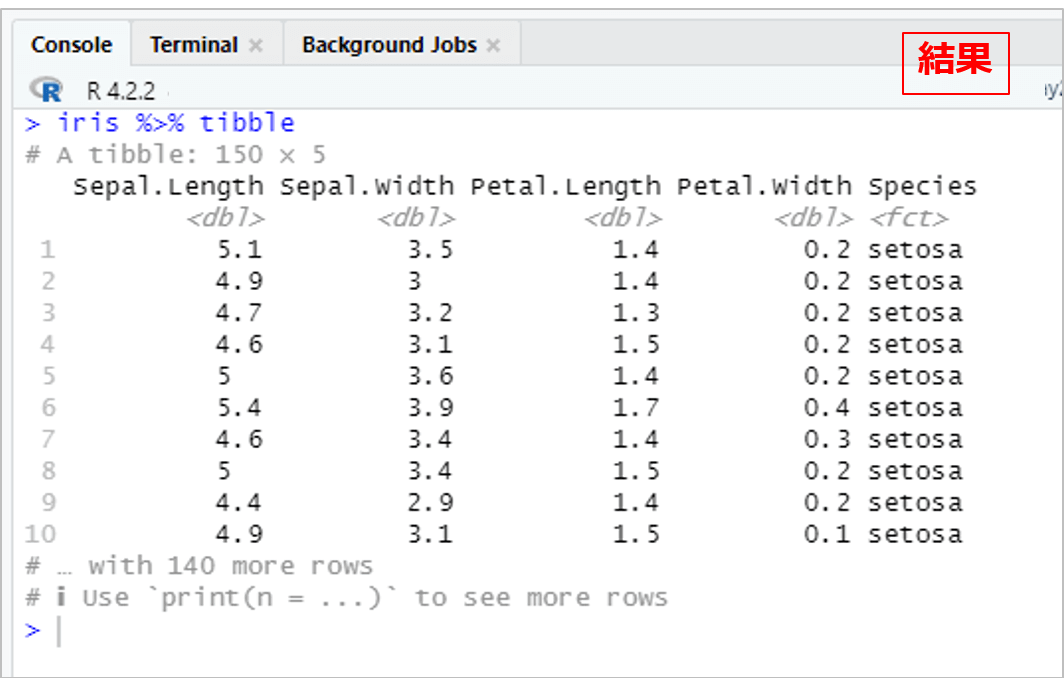
はじめに、データの中身を見てみます。
iris %>% tibble # %>%(パイプ演算子):irisのデータをtibble関数に入れる # tibble関数:データ構造を作成。今回は150行×5列だとわかった。
次に、データの基礎統計量(平均、最小値、最大値など)を見てみます。
iris %>% summary # summary関数:データの基礎統計量の算出

続いて、データの中身を表で見てみます。
iris %>% view # view関数:データの中身を見る
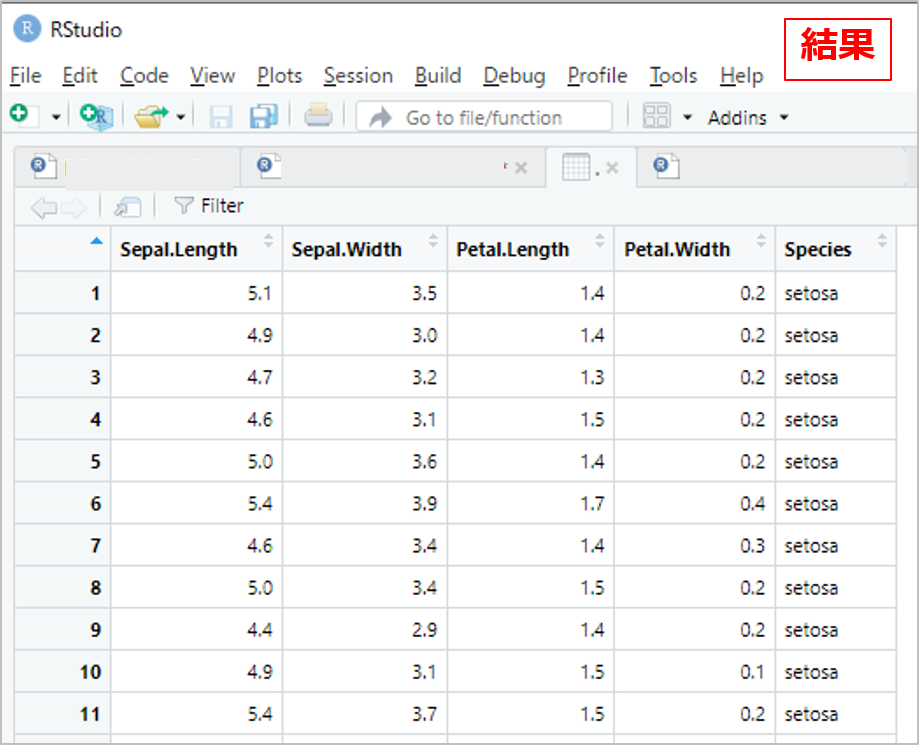
ちなみに、
- Sepal.Length → がくの長さ
- Sepal.Width → がくの幅
- Petal.Length → 花びらの長さ
- Petal.Width → 花びらの幅
- Species → 種類(setosaという種類のアヤメ)
となります。
グラフを描いてみる
ここからは、実際にグラフを描いてみます。
- 棒グラフ
ggplot(data=iris, aes(x=Species, y=Petal.Length)) + geom_bar(stat='identity')
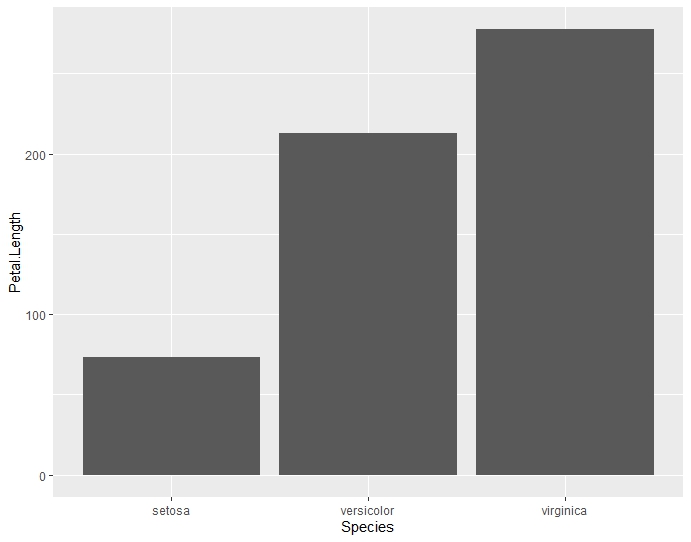
メモ
- aes:グラフを描くときに、xとyの位置や線の色を決める
- geom_bar:棒グラフ
- statistics:数値の処理 ※棒グラフでは基本的に”identity”に設定する
geom_barのstatistics(数値の処理)は、基本的にidentityと設定します。
何も設定しないと、stat=‘count’(データの個数を描く)になるんですが、これだとエラーになります。
また、以下のコードは、すべて同じ棒グラフを描くことが可能です。
↓さっきと同じコード
ggplot(data=iris, aes(x=Species, y=Petal.Length)) + geom_bar(stat='identity')
↓gに代入するコード
g <- ggplot(data=iris, aes(x=Species, y=Petal.Length)) + geom_bar(stat='identity') g
↓パイプ演算子を使うコード。連続した処理のあとに描きたいとき便利。
iris %>% ggplot(aes(x=Species, y=Petal.Length)) + geom_bar(stat='identity')
- ヒストグラム
Petal.Length(花びらの長さ)のヒストグラムを描いてみます。
ヒストグラムは変数がひとつなので、aes()の中身はひとつだけになります。
iris %>% ggplot(aes(Petal.Length)) + geom_histogram()
ビン幅(棒の幅)を変えてみると、、、
iris %>% ggplot(aes(Petal.Length)) + geom_histogram(binwidth=0.05)
「binwidth=0.05」により、棒の幅が狭くなりました。
さらに、母集団で見たらどんな値になっているのかを推定した値も、一緒に表示させることができます。
iris %>% ggplot(aes(x=Petal.Length, y=..density..)) + geom_histogram(binwidth=1, alpha=0.5, position="identity")+ geom_density()
「geom_density()」をつけることで、曲線を表示できました。
ちなみに「alpha」は透過率です。
「alpha=0.5」としたので、棒グラフの灰色が薄くなりました。
さらに、アヤメの種類によって、色分けしたヒストグラムを描いてみます。
iris %>% ggplot(aes(x=Petal.Length, fill=Species)) + geom_histogram(alpha=0.5, position='identity') #透過あり

「fill=Species」を加えることで、種類別に表示できました。
ヒストグラムを見ると、種類によってPetal.Length(花びらの長さ)が異なる傾向にあるとわかります。
「setosa」は比較的、Petal.Length(花びらの長さ)が短いものが多いです。
- 箱ひげ図
Petal.Length(花びらの長さ)の箱ひげ図を描いてみます。
iris %>% ggplot(aes(y=Petal.Length, x=Species, fill=Species)) + geom_boxplot(alpha=0.5)
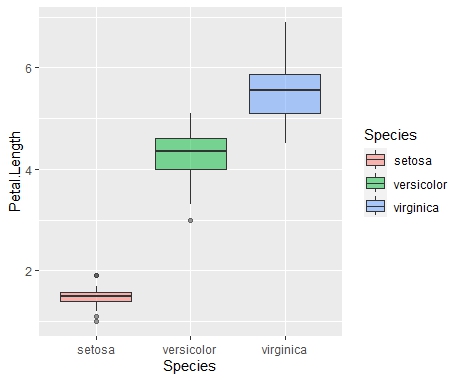
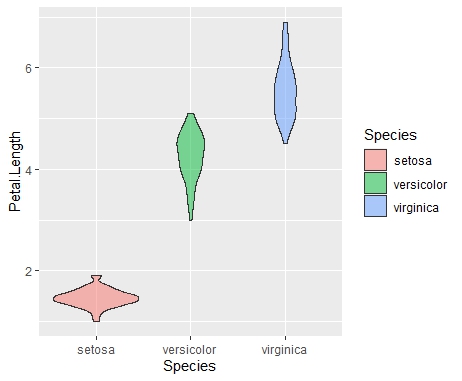
- バイオリンプロット
Petal.Length(花びらの長さ)のバイオリンプロットを描いてみます。
iris %>% ggplot(aes(y=Petal.Length, x=Species, fill=Species)) + geom_violin(alpha=0.5)
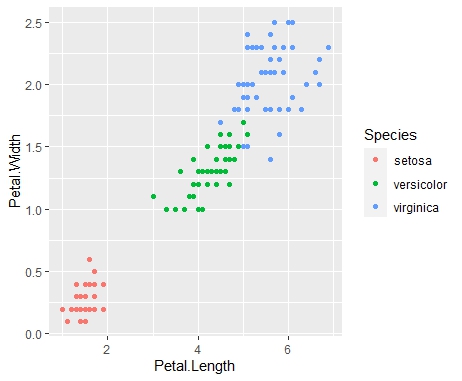
- 散布図
Petal.Length(花びらの長さ)とPetal.Width(花びらの幅)の散布図を描いてみます。
iris %>% ggplot(aes(x=Petal.Length, y=Petal.Width, colour=Species)) + geom_point()
ggplotのグラフ
- 棒グラフ:geom_bar
- ヒストグラム:geom_histogram
- 箱ひげ図:geom_boxplot
- バイオリンプロット:geom_violin
- 散布図:geom_point
- グラフの色付け&透過も可能
マトリックスを描いてデータの関係性を調べる
変数が複数あるときに、それぞれの変数同士でどんな相関があるのかを把握したいときにはマトリックス(行列の形式に並べた図)を使うのが有効です。
- 散布図のマトリックス
「iris(アヤメ)」のデータの散布図マトリックスを描いてみます。
iris %>% ggpairs
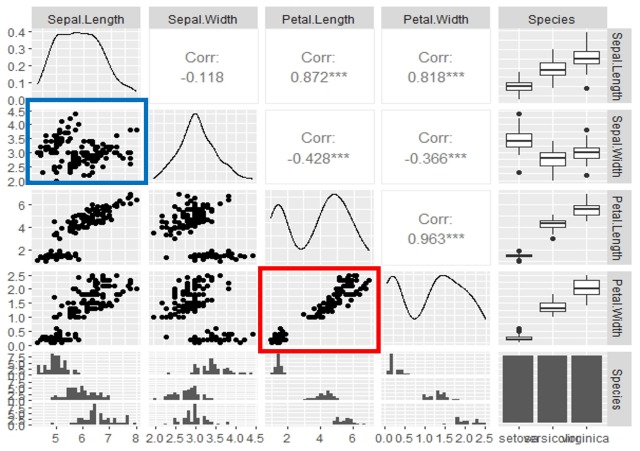
赤い四角のところは、「Petal.Width」と「Petal.Length」の相関を表しています。
右肩上がりの線が書けそうなので、強い正の線形の関係があるとわかります。
一方、青い四角のところは「Sepal.Width」と「Sepal.Length」の関係を表しています。
データがバラついていて、相関関係が弱そうに見えます。
そこで、本当に「Sepal.Width」と「Sepal.Length」は関係がないのか、Species(種類)ごとに見てみましょう。
iris %>% ggpairs(mapping=aes(colour=Species, alpha=0.3))
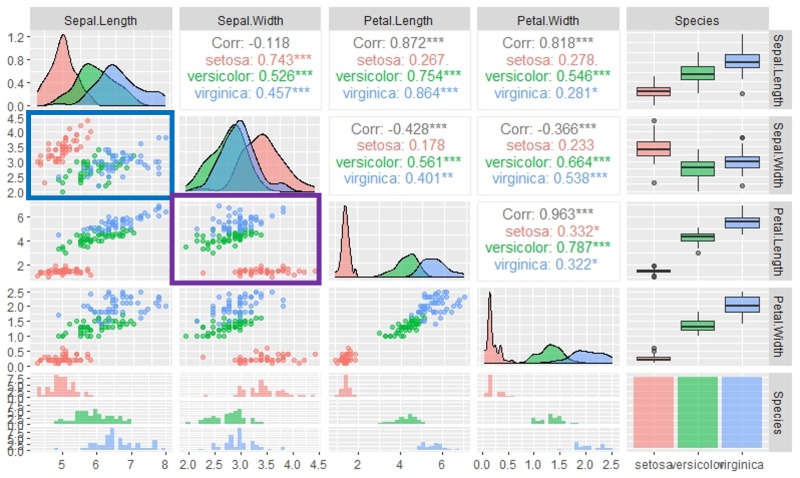
青い四角の「Sepal.Width」と「Sepal.Length」は、種類ごとに見てみると、それぞれで正の線形の関係があるとわかりました。
また、紫の四角の「Sepal.Width」と「Petal.Length」も、強い正の線形の関係があります。
Speciesごとに分割することによって、相関関係がきれいに抽出できそうです。
R学習②:EDA:探索的データ解析

Rによる可視化(ggplot)の基本を学んだうえで、次は実際にデータを分析する演習がありました。
講義では、あらかじめ用意されたデータを使って、散布図マトリックスを描いて分析が進められました。
本記事では、別のデータセットを使って、データ分析をやってみたいと思います。
データセットについて
R言語には、あらかじめサンプルのデータセットが用意されています。
サンプルのデータセットについて、日本語でまとめてくれているサイトはこちらです。
こちらのデータセットからデータを選んで、分析してみます。
データセット「attenu」:地震のピーク加速度
「attenu」という、地震のピーク加速度のデータを使ってみます。
まずはデータを読み込みます。
data(attenu)
データを読み込んだら、どんなデータなのか見ていきます。
attenu ### データ一覧。 attenu %>% view ### 表が出力される attenu %>% glimpse ### 横方向にデータの一覧を見れる attenu %>% summary ### 要約統計量
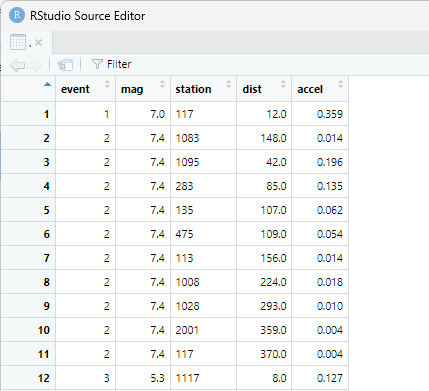
「attenu %>% view」で表示された表はこちら。
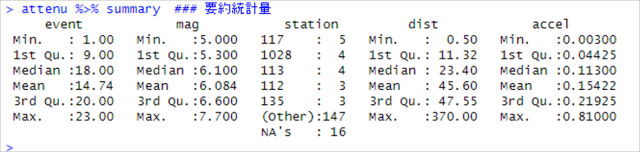
「attenu %>% summary」で表示された要約統計量はこちら。
各項目については、こちらのサイトにも記載されています。
- event:1~23の数字。23の地震が発生した。(数値データ)
- mag:モーメントマグニチュード。最小は5、最大は7.7。(数値データ)
- station:位置番号。(カテゴリーデータ)
- dist:震源から観測点までの距離。単位は「km」。(数値データ)
- accel:ピーク加速度。単位は「g」。(数値データ)
データの概要が把握できました。
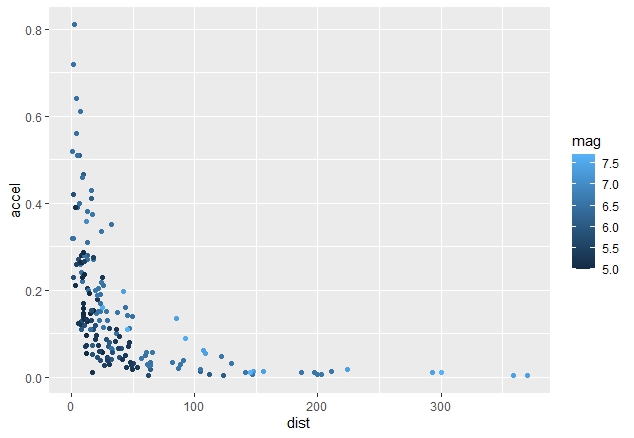
ここからは、「距離が遠くなると、加速度はどのくらい減衰するのか?」ということを知るために、分析していきます。
- 散布図
横軸は距離、縦軸は加速度、マグニチュードで色分けしてみました。
attenu %>% ggplot(aes(x=dist, y=accel, colour=mag)) + geom_point()
まとめ:Rでグラフを描く&分析する!
今回は、(株)データミックス「気象データアナリスト養成講座」の、講義2日目の内容をまとめました。
講義2日目の内容
- Rによる可視化(ggplot)の基本を習得する
- 棒グラフやヒストグラムを描けるようにする
- 散布図マトリックスの描画・分析をできるようにする
グラフや散布図の作成は、慣れるまで難しく感じました。
しかし、わからないときはググってみると、色んな情報が出てきて参考になりました。
データミックス![]() では、講義動画を何度も見返すことができるので、復習しやすいです。
では、講義動画を何度も見返すことができるので、復習しやすいです。
来週の講義もがんばりたいと思います。
講義前半の「統計的・確率的アプローチ」には、以下の記事をご参照ください。