
本記事では、(株)データミックスの「気象データアナリスト養成講座」を受けた感想や、講義メモをまとめます。
今回は、2023年4月1日に受けた、ベーシックステップ3日目の内容です。
分析プロジェクトの進め方

分析プロジェクトには2つのタイプがあります。
- アドホック型:いったん自分の手元でやってみる
- 実装型:サービスに適用していく
いきなり実装型をするのではなく、一度は自分の手元でデータを確認・分析し、仮説を立てることが大切です。
アドホック型でおこなったものを定期的にモニタリングして、必要に応じて実装していきます。
また、予測モデルを活用するさいに、意識しておくべきこともあります。
検討すべきこと
- 予測モデルのビジネス的な評価軸の設定
- モデルを使うのがベストかどうかわからない
- はじめはシンプルに。次第に複雑化させていく
モデルでは、決定係数などの評価軸があります。
しかし、ビジネスの現場で予測モデルを活用するときは、「売上が〇%上がった」「コストが〇円下がった」などビジネス的な評価軸が必要です。
また、データを集める→要約統計量をチェック→モデルを作る→システムに実装→運用する、というトータルのコストを考えたときに、本当にモデルを作ったほうが利益が出るのか、ということも考えなくてはいけません。
いきなり複雑なモデルを作ってしまうと後戻りは大変なので、はじめはシンプルなモデルを作ることも大切なようです。
教師あり学習

機械学習は、3つにわけることができます。
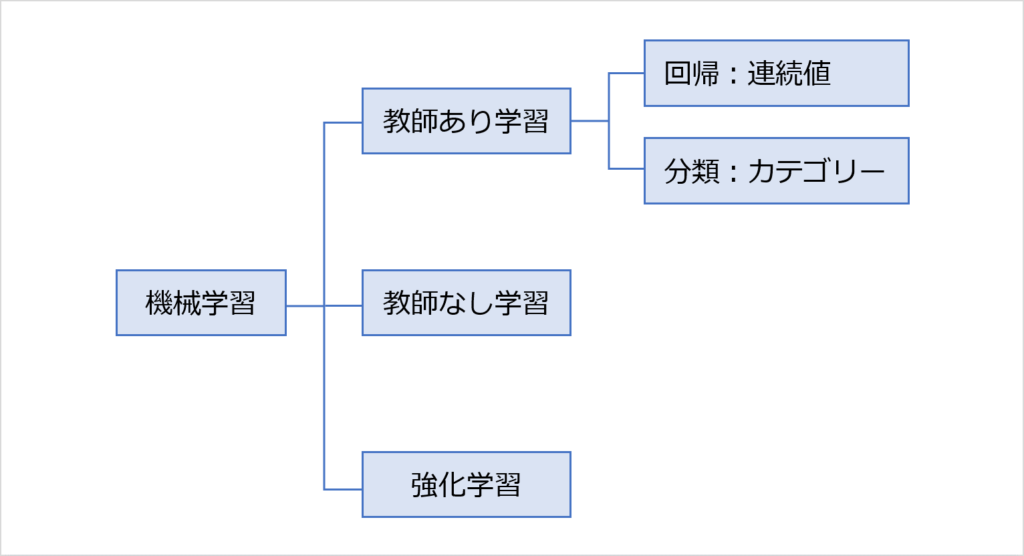
「教師あり学習」には、正解となるデータがあります。
たとえば、あらかじめ大量の動物の画像を読み込ませて「これは猫」「これは犬」「これは馬」...というようにラベリングして、それを正解データとします。
そして新しい画像を読み込ませたときに、正解データの中から一致するデータを見つけ出して、どの動物か判定させます。
正解データと予測値はどうしてもズレてしまう部分はありますが、そのズレを最小化するように、モデルのパラメーターを決めていきます。
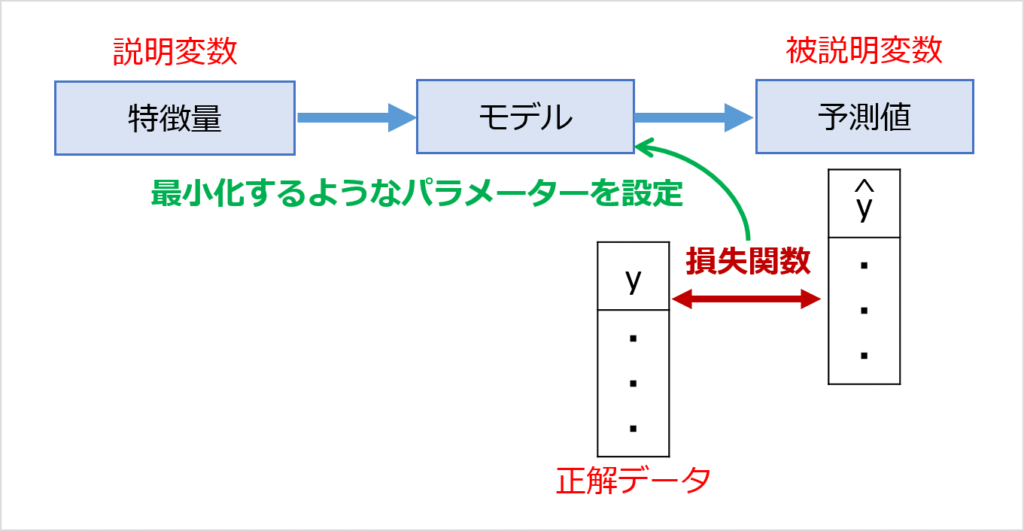
また、「教師あり学習」のアルゴリズム(処理方法)には、いくつか種類があります。
| アルゴリズム | 分類 | 回帰 |
|---|---|---|
| 線形回帰 | ✕ | 〇 |
| 正則化 | ✕ | 〇 |
| ロジスティック回帰 | 〇 | ✕ |
| ランダムフォレスト | 〇 | 〇 |
| サポートベクトルマシン | 〇 | 〇 |
| カーネル法 | 〇 | 〇 |
| ナイーブベイズ | 〇 | ✕ |
| ニューラルネットワーク | 〇 | 〇 |
| kNN | 〇 | 〇 |
今回の講義では、「分類」問題について扱われました。
二値分類と多値分類
分類のなかには「二値分類」と「多値分類」があります。
分類が2つ(合格/不合格など)のものは「二値分類」、3つ以上は「多値分類」です。
二値分類も多値分類も、基本的な考え方は変わらないようです。
足し合わせたら1になる確率を考えて、モデルの予測結果とします。

真偽の場合分け(混同⾏列)
二値分類の予測の精度指標として、混同⾏列があります。
※おそらく気象予報士試験に出てきた「予報と実況の対比表」のような考え方だと思います。
混同⾏列は「分類」用の指標です。
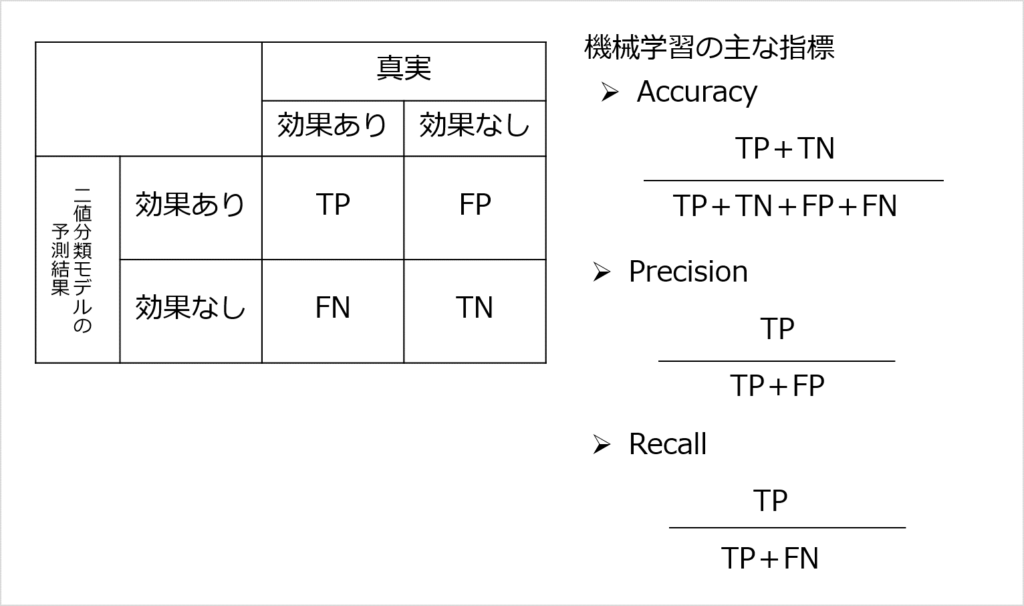
- Accuracy:「全体」の予測の正確さ
- Precision:「効果ありと予測したもの」の正確さ
- Recall:本来効果のあるもののうち、どれだけを予測上効果ありとカバーできたか
おもな損失関数
どんな損失関数を使うかは、データの特徴や問題設定に合わせて選択していきます。
おもな損失関数
- 残差の⼆乗平均:MSE(回帰)
- 残差の⼆乗平均の平方根:RMSE(回帰)
- 残差の絶対値の平均:MAE(回帰)
- 正しい分類は0、誤った分類は1:0-1Loss(分類)
- 正解から遠いほど指数的に悪いと評価:Cross Entropy Error(分類)
モデルの評価指標と、ビジネス的なKPIとの繋がりを考えるのが、実務では大切なようです。
予測モデルの課題
機械学習で予測モデリングを作るにあたって、気をつけなければいけないことがあります。
おもな注意点
- オーバーフィット&アンダーフィット
- データリーケージ
- EDAの重要性
オーバーフィット&アンダーフィットは、このあと詳しく見ていきます。
データリーケージとは、モデル作成時にはわからないデータを、モデル学習時に使用してしまうことです。
たとえば、がん診断の結果が良性か悪性か予測するモデルを作るさいに、「抗がん剤治療予定の有無」を変数に入れると、モデルの精度が不自然に上がってしまいます。
「抗がん剤治療の予定」は、がん診断の結果を聞いた後に判断するので、モデル作成時にはわからないはずです。
また、EDA(探索的データ分析)をやらずに、データをよく見ないでモデルに入れてしまうのもNGです。
データの特徴や分布を見ることで、そもそもモデルに入れていいデータかどうか判別できることがあります。
オーバーフィット&アンダーフィット

オーバーフィットは過学習、アンダーフィットは学習不足の状態です。
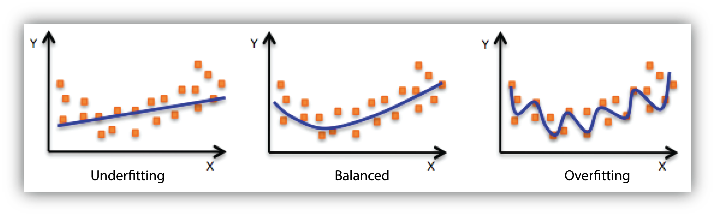
アンダーフィットは、分布を捉えられていない状態です。
オーバーフィットは、一見データを細かく捉えていてよさそうですが、学習時のデータに過剰にフィットしています。
そのため汎用性がなく、新たなデータにモデルをあてはめたときに誤差が大きくなってしまいます。
バランスのよいモデルを作成するためには、以下の3つの観点に着目するのが大切です。
モデルを学習させる観点
- データの「行」(サンプル)
- データの「列」(変数)
- モデルそのもの(関数)
それぞれ詳しく見ていきます。
データの「行」(サンプル)
データの「行」に着目して、オーバーフィットしないモデル作成を考えます。
具体的には、モデル用のデータを分割することで、サンプルへの過剰なフィットを防ぎます。
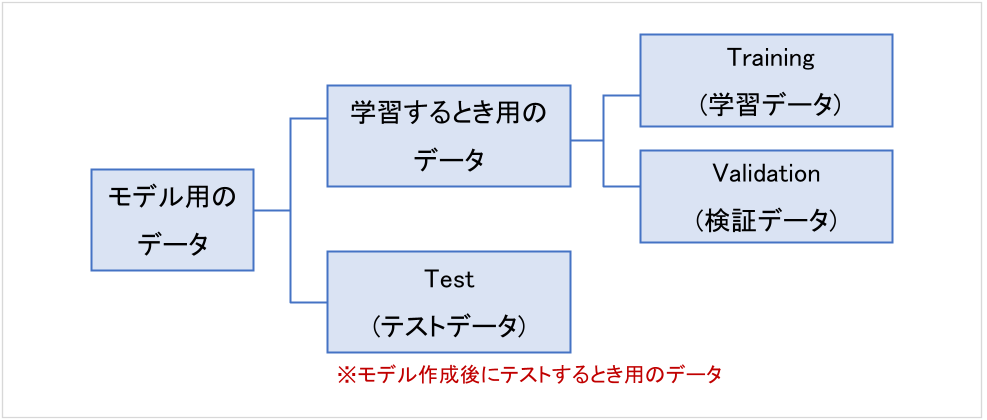
まずは「学習するとき用のデータ」と「テストデータ」に分けます。
さらに、モデルを複数つくるときには、「学習するとき用のデータ」を「学習データ」と「検証データ」に分けます。
つまりモデル間の比較をするためには3つに分ける必要があります。
なぜなら、「学習データ」と「テストデータ」に2分割した状態で2つのモデルを作ると、テストデータにオーバーフィットしてしまうことがあるからです。
たとえば…
2つのモデルを作って、どちらが精度が高いか検証する場合を考えます。
- 「学習データ」と「テストデータ」に2分割する
- 「学習データ」でモデル1を作成→「テストデータ」で検証
- 「学習データ」でモデル2を作成→「テストデータ」で検証
上記の場合、「テストデータに対して精度が良いかどうか」を見てしまうので、モデル2の精度が高くなります。
目安としては、「学習するとき用のデータ」は80%、「テストデータ」は20%の割合で分けるようです。
- データの分け方
データの分け方として、ランダムに分ける方法があります。
ただしデータ同士に依存関係がある場合は、ランダムに分けるのはNGです。
"データ同士に依存関係がある場合"とは、たとえば体重データが挙げられます。
体重データは前日のデータの続きになるので、ランダムに分けてしまうと、データの関係性が崩れてしまいます。
このような場合は、時間軸に沿って、前半を「学習するとき用のデータ」、後半を「テストデータ」に分ける方法があります。
- 不均衡データ
"大量に生産されたネジの不良品"などは、数千~数万個に1個しか不良品が発生しないことが多いです。
このように、正常品と不良品の数に極端な差があるようなデータは、不均衡データです。
不均衡データでモデルを学習させると、数の多いデータにつられてしまいます。
そのため、サンプル数をどちらかに近づけて調整をおこなう必要があります。
データの「列」(変数)
データの「列」に着目して、オーバーフィットしないモデル作成を考えます。
列のなかに、(不要な変数を含めて)大量に特徴量があると、過学習しやすくなります。
そのため、本当に必要な変数のみを選択するのが大切です。
変数の選択方法はいくつかありますが、授業では主に2つの方法について解説がありました。
- 変数増減法:ステップワイズ法
変数を一つずつ増やしながら(または減らしながら)、精度を見ていく方法です。
この方法には注意点があります。
例えば変数1を選んでから、変数2、変数3、、、と一つずつ増やした場合、「変数1を選ばなかった場合」は検証できません。
しかしステップワイズ法は計算が早いというメリットがあるため、よく使われる手法です。
- 正則化:ラッソ回帰
観測されたデータ数が少ないとき、モデルはオーバーフィットしやすいです。
これを回避するために、モデル学習するときに、学習する度合いを緩めることで過学習を抑えることができます。
モデルそのもの(関数)
バランスのよいモデルを作成するための観点として、モデルそのものに着目する方法があります。
具体的には、モデルを追加することで最適なモデルにしていきます。
授業では「決定木」について詳しい解説がありました。
決定木

決定木は、学習データを条件分岐によって分割していく手法です。

決定木の学習は、空間の分割を繰り返すことでおこなわれます。
学習のイメージは以下の通りです。
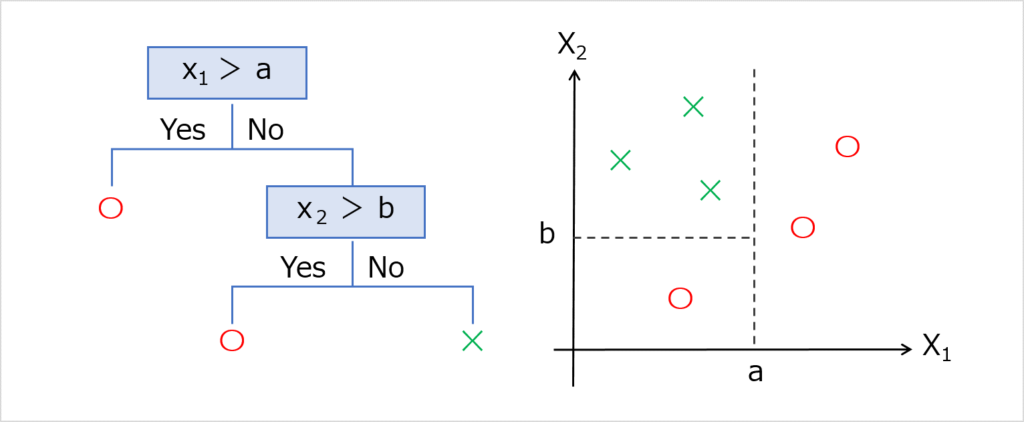
なるべくデータの純度が高くなるように、分割していきます。
「純度が高くなる」とは、不適当なデータが少なくなるような分け方です。
分割したエリア内の純度が、モデルで予測されるスコアの推定値になります。
- 注意点
「データ1つあたり、エリア1つ」になるよう分割していくと、必ず純度100%になります。
しかし、この分け方は過学習になります。
そのため「最大の深さを決める」「最小のサンプルサイズを決める」などのチューニングが必要です。
決定木の拡張

決定木から拡張したアルゴリズムを見ていきます。
決定木の拡張
- ランダムフォレスト
- アダブースト
「ランダムフォレスト」も「アダブースト」も、決定木を複数使う方法(アンサンブル学習)です。
それぞれ詳しく見ていきます。
ランダムフォレスト
ランダムフォレストは、複数の決定木モデルを作って多数決をとることで、予測精度を向上させる方法です。
アンサンブル学習の手法として、おもに「バギング」を使います。
- バギング
「ブートストラップ(Bootstrap)」という方法を使って、複数のモデルを並列的に学習させる手法を「バギング(Bootstrap Aggregating)」といいます。
ブートストラップは、元のサンプルデータを⺟集団のように見立てて、繰り返しサンプリングするやり方です。
ブートストラップのサンプルで複数のモデルを作成し、その結果をまとめて出力するのがバギングです。
アダブースト
アダブーストは、決定木を使ってブースティングを実行する方法です。
浅い⽊を⼤量に作成し、それをまとめて最終的な出力結果にします。
- ブースティング
「ブースティング(Boosting)」は、学習を直列的に進めていく手法です。
前に作ったモデルの結果を参考にして、次のモデルを構築していきます。
バギングのように複製するのではなく、前に作ったモデルの結果で誤った観測に重み付けをすることで、新しいモデルを作成します。
バギングよりも時間がかかりますが、精度が高くなることが期待できます。
まとめ:教師あり学習
今回は、(株)データミックス「気象データアナリスト養成講座」の、ベーシックステップ3日目の内容をまとめました。
ベーシックステップ3日目の内容
- 教師あり学習には「正解データ」が存在する
- モデル作成時には過学習や学習不足に注意する
- 決定木モデルは、学習データを条件分岐によって分割する手法
- ランダムフォレストは、複数の決定木モデルを使う手法
今回の講義では、教師あり学習に関する基礎内容や具体的な注意点を学びました。
来週の講義もがんばりたいと思います。